Apache Kafka is an open source distributed streaming platform, that allows for the development of real-time event-driven applications. Specifically, it allows developers to make applications that continuously produce and consume streams of data records.
Now, Kafka is distributed. It runs as a cluster that can span multiple servers or even multiple data centers. The records that are produced are replicated and partitioned in such a way that allows for a high volume of users to use the application simultaneously without any perceptibale lag in performance.

Characteristics of Apache Kafka
- It Produce and consume streams of data.
- Apache Kafka is super fast.
- It also maintains high level of accuracy with the data records.
- Apache Kafka maintains the order of data records occurance.
- Because it's replicated, Apache Kafka is also resilient and fault-tolerant.
So, these characteristics all together add up to an extremely powerful platform.
Deep dive into Kafka's architecture
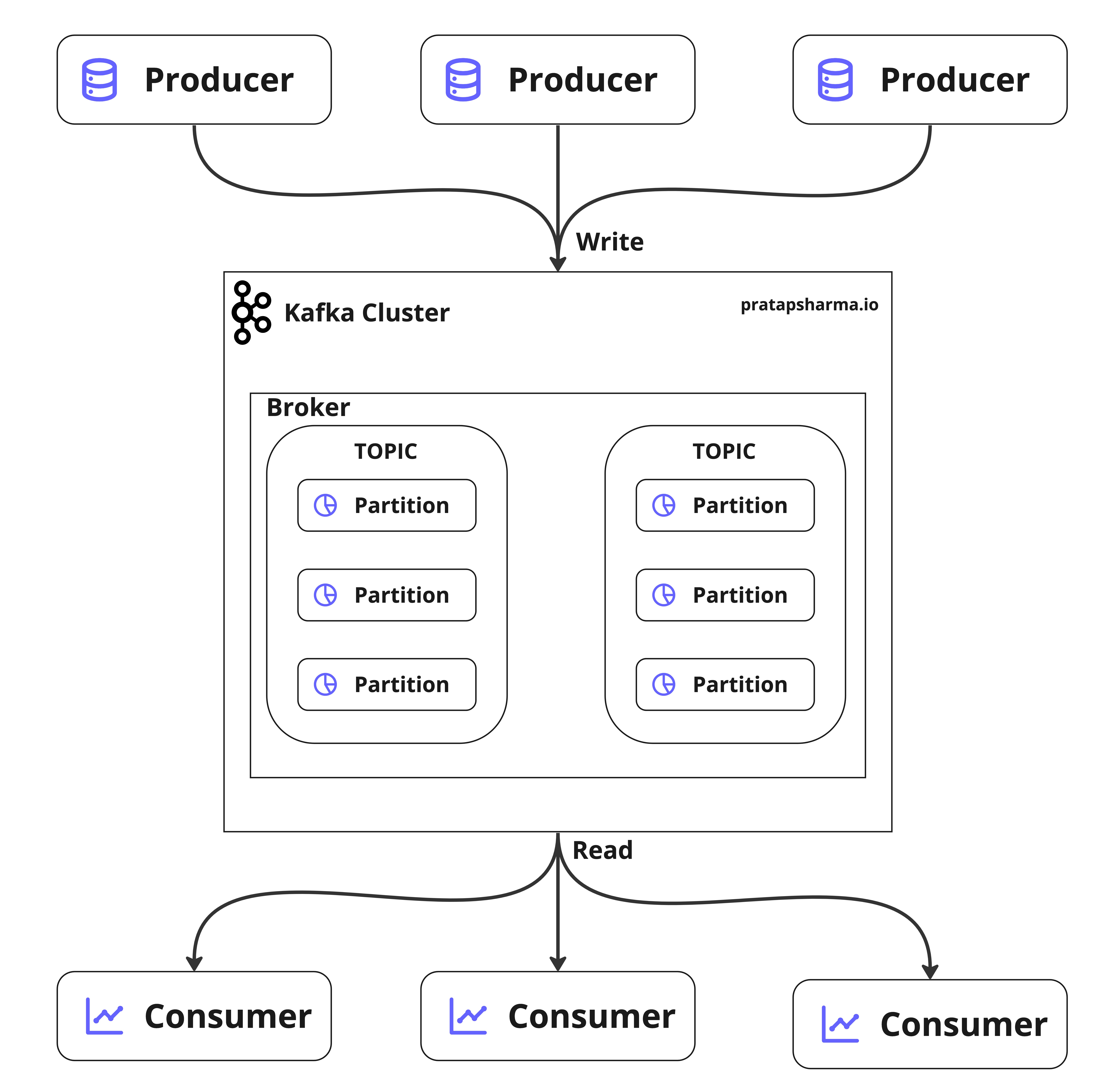
Brokers Basics
- Messages are produced by a producer and sent to brokers.
- Brokers receive and store messages in a Kafka cluster.
- A Kafka cluster can have multiple brokers, which work together to handle incoming messages and distribute them across the cluster.
- Each broker in the cluster is responsible for managing multiple partitions, which are logical units that allow messages to be distributed and stored in a scalable way.
Kafka has four APIs:
- Producer API: publishes a stream of records to a Kafka topic.
- Consumer API: subscribes to topics and process their streams of records.
- Streams API: enables stream processors to transform input streams from topic(s) to output streams, which are directed to different output topics.
- Connector API: automates the addition of another application or data system to Kafka topics, making it easy for users to integrate their existing systems with Kafka.
How does Kafka work?
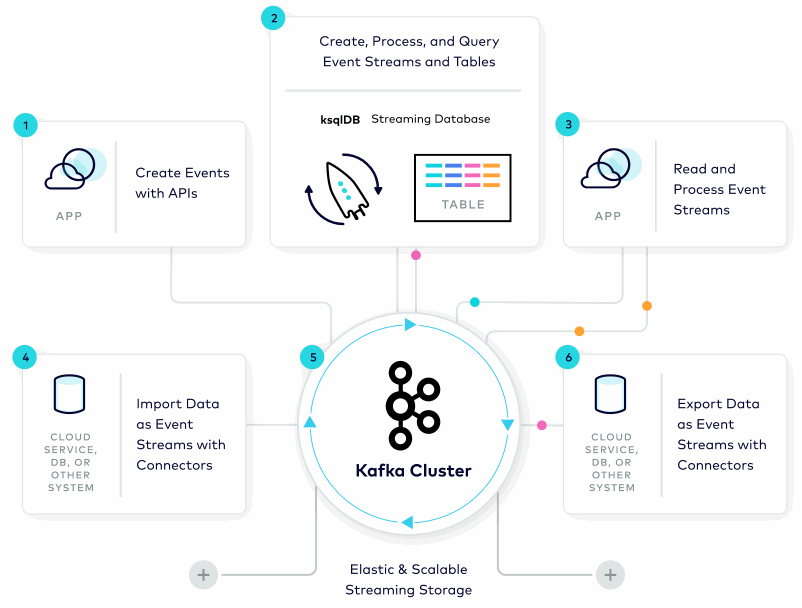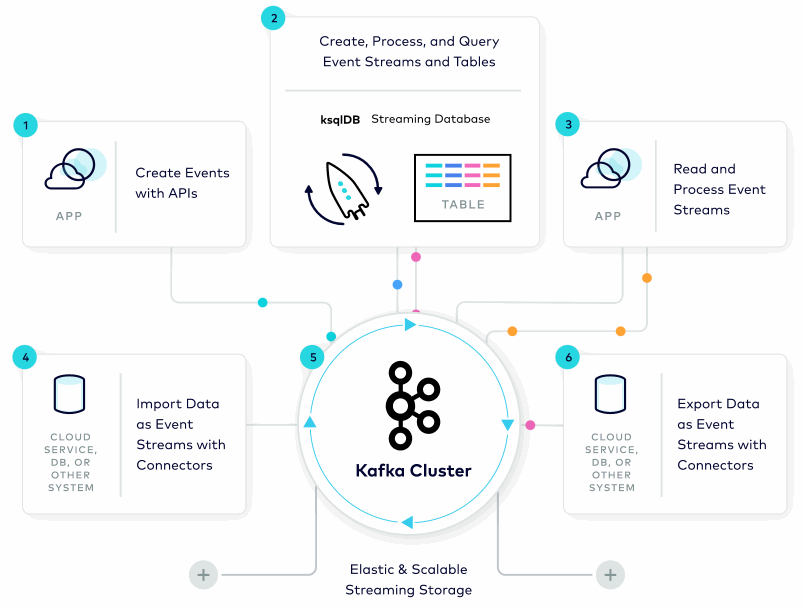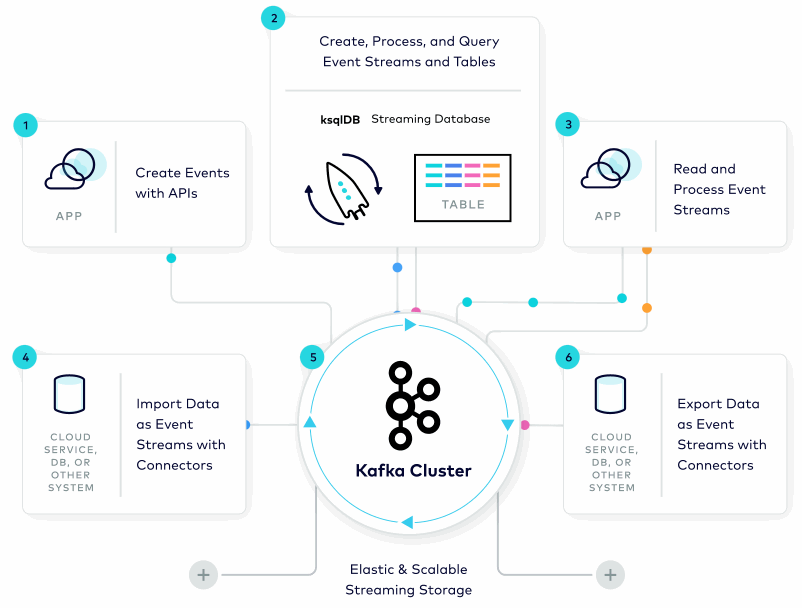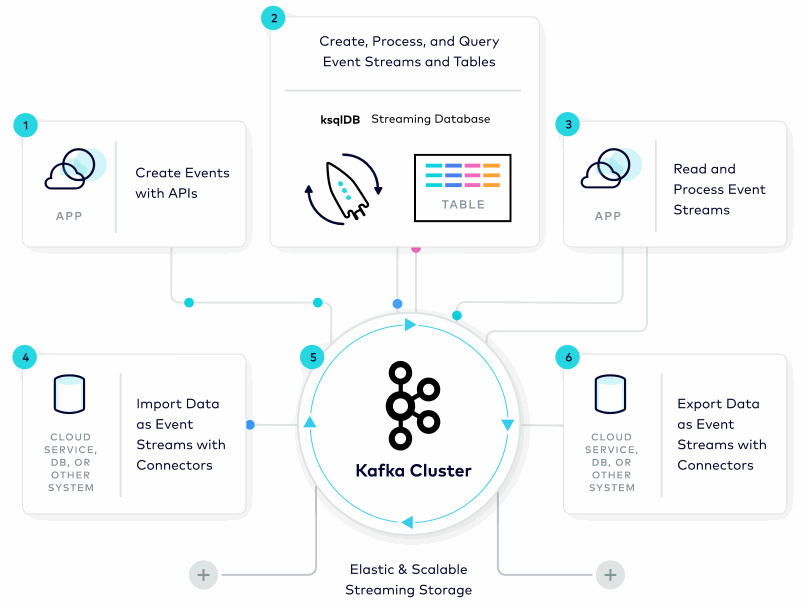
Image source : https://www.confluent.io
The architecture of Kafka is built around the concept of topics, which are essentially named feeds or channels. Producers publish messages to a topic, and these messages are stored in a distributed, partitioned log. Each message is assigned a sequential ID, which represents its position in the log.
Consumers can then subscribe to a topic and receive messages from it. Each consumer is assigned to one or more partitions of a topic, and the messages are delivered to the consumer in the order they were written to the partition. This makes Kafka highly scalable, as it can distribute the workload across multiple servers and parallelize the processing of messages.
Kafka uses a publish-subscribe model to send messages between producers and consumers. The producers publish messages to a topic, and the messages are sent to all consumers that have subscribed to that topic. This model allows for multiple consumers to process messages simultaneously, making Kafka highly efficient for real-time data processing.
Kafka also provides fault-tolerance through replication. Each partition is replicated across multiple servers, ensuring that there are multiple copies of the data available in case of failure. This makes Kafka highly reliable, as it can continue to function even in the event of a server failure.
Use Cases
Kafka finds its primary use in building two types of applications:
-
Firstly, real-time streaming data pipelines that can move millions of data or event records between enterprise systems at a large scale and in real-time. Kafka ensures reliable data movement without the risk of data corruption, duplication, or other such problems that can occur when processing such vast volumes of data at high speeds.
-
Secondly, real-time streaming applications that generate streams of their own and are driven by record or event streams. Examples of such applications can be found everywhere online, from retail websites that continually update product availability in local stores to personalized recommendation or advertising sites that rely on clickstream analysis.
Overall, Kafka's architecture is uniquely suited to support these kinds of high-volume data processing applications, making it a top choice for developers looking to build reliable, scalable, and efficient data pipelines.
Conclusion
Kafka is a powerful distributed streaming platform that enables real-time data processing, fault-tolerance, and scalability. Its architecture is designed to handle high volume data feeds and enable real-time processing. With topics, partitions, and a publish-subscribe model, Kafka enables producers to publish messages and consumers to receive them in real-time. This makes Kafka highly efficient, scalable, and reliable, making it ideal for building real-time streaming data pipelines and applications. With its robust architecture and APIs, Kafka is well-suited for modern data-driven enterprises.
System Design Series
- Why is System Design Important?
- Architecture and Design Principle for Online Food Delivery System
- Building Real-time Applications with Redis Pub/Sub
- Understanding Proxies: The Differences Between Forward and Reverse Proxies
- Eventual Consistency vs Strong Consistency: Distributed Systems
💌 If you'd like to receive more tutorials in your inbox, you can sign up for the newsletter here.
Please let me know if there's anything else I can add or if there's any way to improve the post. Also, leave a comment if you have any feedback or suggestions.
Discussions